Burp Suite Basics
任务1:运行Burp Suite并连接到目标Web应用程序
在Firefox中,将 Burp 设置为浏览器的代理。
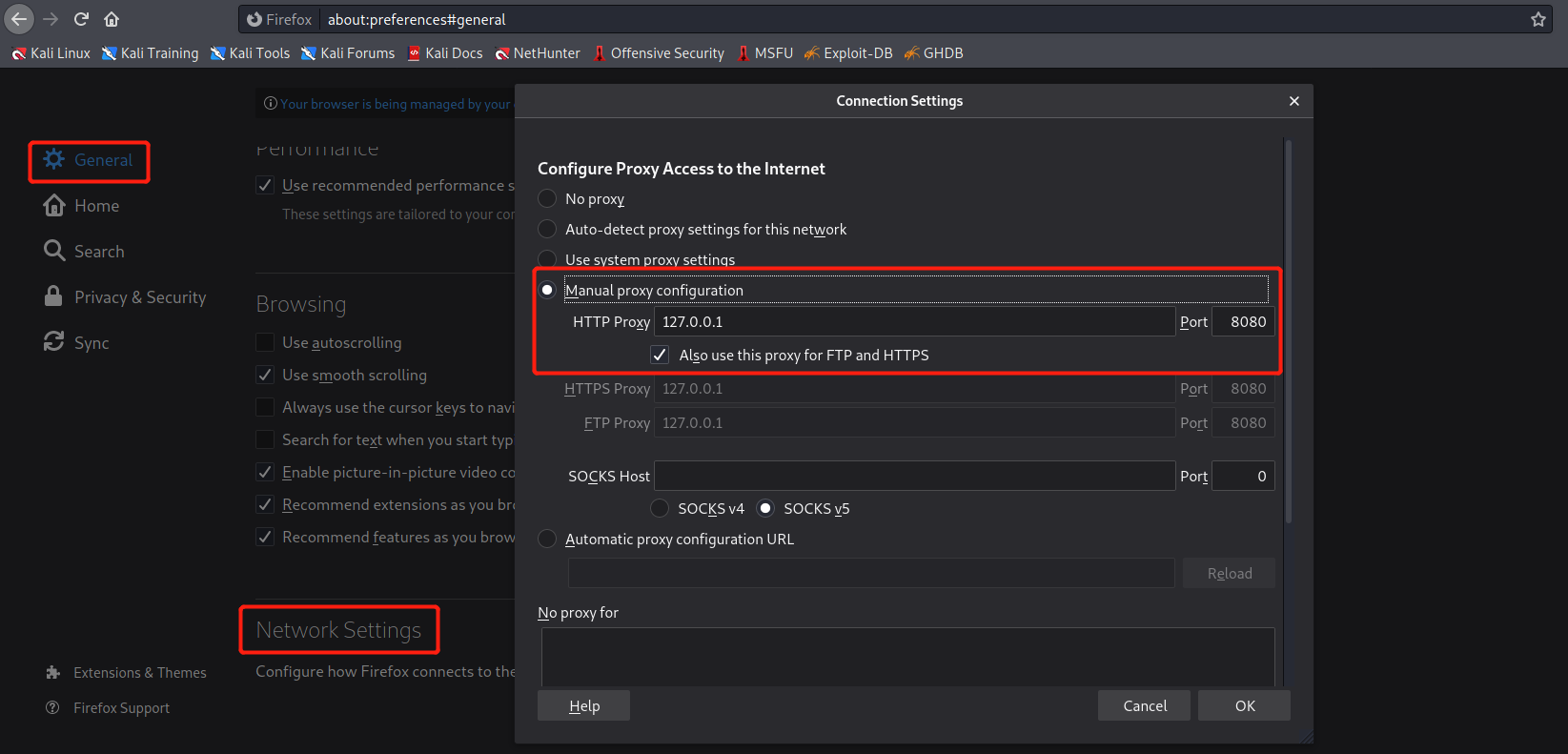
也可以使用扩展FoxyProxy。
任务 2:对网站进行侦察活动
在 Firefox 上,您可以按Ctrl + U在新窗口中浏览页面的源代码。
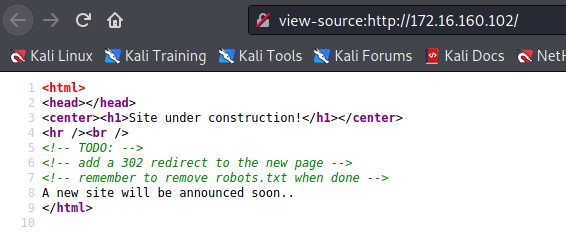
什么是 robots.txt 文件
如果您不希望抓取工具访问您网站中的部分内容,可以创建包含相应规则的 robots.txt 文件。robots.txt 文件是一个简单的文本文件,其中包含关于哪些抓取工具可以访问网站的哪些部分的规则。
如果其他网站上有链接指向被 robots.txt 文件屏蔽的网页,则此网页仍可能会被编入索引。若要阻止你的网址出现在搜索结果中,你应该为服务器上的文件设置设置密码保护、使用“noindex”阻止搜索引擎编入索引。
和其他网址一样,robots.txt 文件的网址也区分大小写。
robots.txt 文件必须是采用 UTF-8 编码的纯文本文件,且各行代码必须以 CR、CR/LF 或 LF 分隔。可以使用Notepad、TextEdit、vi 和 emacs 可用来创建有效的 robots.txt 文件。请勿使用文字处理软件。
语法
#字符:注释,后面的所有内容都会被忽略。
user-agent:标识规则适用的抓取工具。
allow:可抓取的网址路径。
disallow:不可抓取的网址路径。
allow 和 disallow 字段也称为”指令”。默认情况下,指定的抓取工具没有抓取限制。
如果指定了 [path] 值,该路径值就是 robots.txt 文件所在网站的根目录的相对路径(使用相同的协议、端口号、主机和域名)。 路径值必须以 / 开头来表示根目录,该值区分大小写。
基于路径值的网址匹配
Google 会以 allow 和 disallow 指令中的路径值为基础,确定某项规则是否适用于网站上的特定网址。为此,系统会将相应规则与抓取工具尝试抓取的网址的路径部分进行比较。
对于路径值,Google、Bing 和其他主流搜索引擎支持有限形式的通配符。这些通配符包括:
*表示出现 0 次或多次的任何有效字符。$表示网址结束。
| 路径匹配示例 | |
|---|---|
| / | 匹配根目录以及任何下级网址。 |
| /* | 等同于 /。结尾的通配符会被忽略。 |
| /$ | 仅匹配根目录。任何更低级别的网址均可抓取。 |
| /fish | 匹配以 /fish 开头的任何路径。 匹配项: /fish /fish.html /fish/salmon.html /fishheads /fishheads/yummy.html /fish.php?id=anything 不匹配项: /Fish.asp /catfish /?id=fish /desert/fish 注意:匹配时区分大小写。 |
| /fish* | 等同于 /fish。结尾的通配符会被忽略。 匹配项: /fish /fish.html /fish/salmon.html /fishheads /fishheads/yummy.html /fish.php?id=anything 不匹配项: /Fish.asp /catfish /?id=fish |
| /fish/ | 匹配 /fish/ 文件夹中的任何内容。 匹配项: /fish/ /animals/fish/ /fish/?id=anything /fish/salmon.htm 不匹配项: /fish /fish.html /Fish/Salmon.asp |
| /*.php | 匹配包含 .php 的任何路径。 匹配项: /index.php /filename.php /folder/filename.php /folder/filename.php?parameters /folder/any.php.file.html /filename.php/ 不匹配项: /(即使其映射到 /index.php) /windows.PHP |
| /*.php$ | 匹配以 .php 结尾的任何路径。 匹配项: /filename.php /folder/filename.php 不匹配项: /filename.php?parameters /filename.php/ /filename.php5 /windows.PHP |
| /fish*.php | 匹配包含 /fish 和 .php(按此顺序)的任何路径。 匹配项: /fish.php /fishheads/catfish.php?parameters 不匹配项: /Fish.PHP |
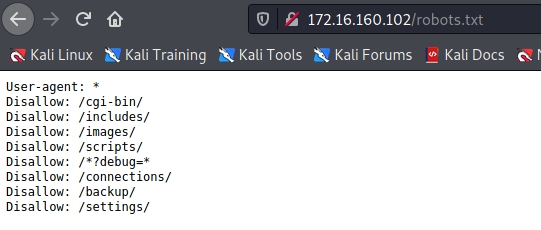
“Disallow”指令意味着网站的开发者不希望网络爬虫在搜索结果中包含应用程序的某些路径。
可以使用Burp Intruder检查robots.txt文件中的路径。
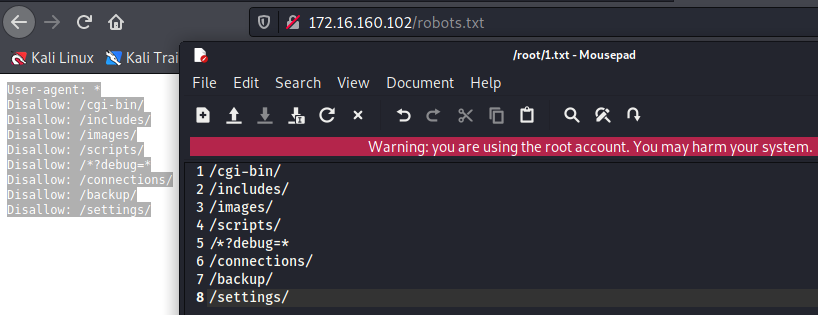
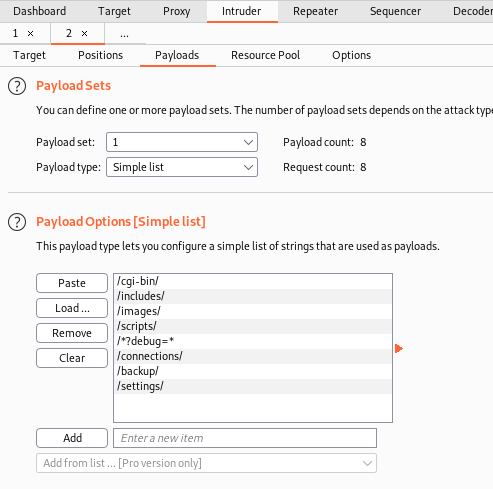
为了防止 Intruder 弄乱有效载荷,向下滚动到页面底部并取消选中“对这些字符进行 URL 编码”。

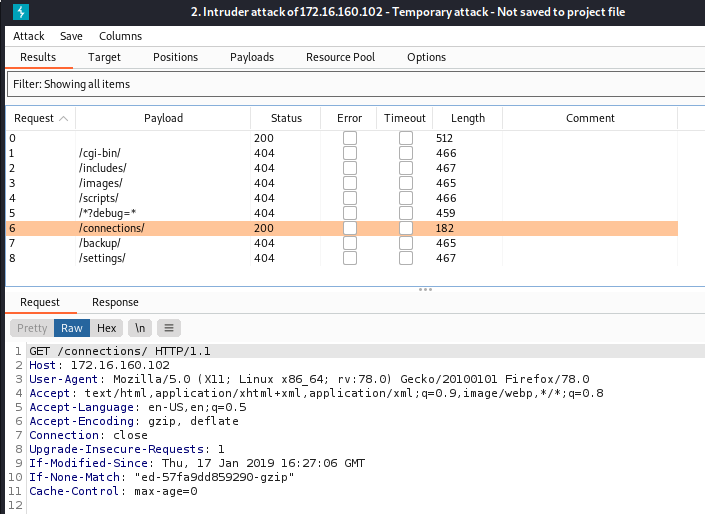
HTTP 代码“200”表示请求的资源存在。
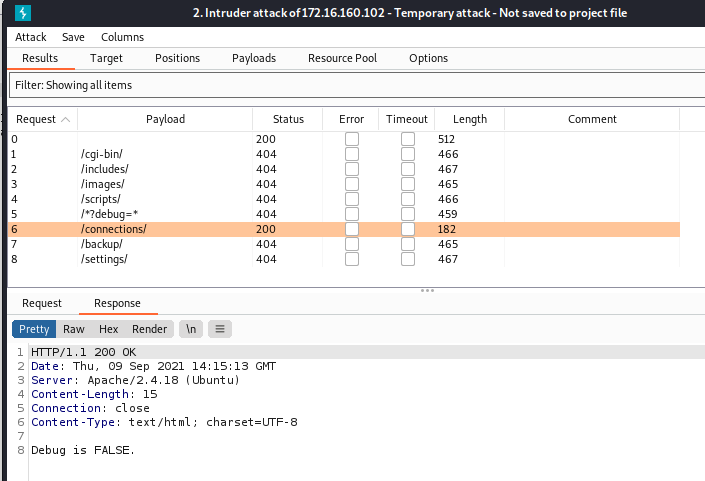
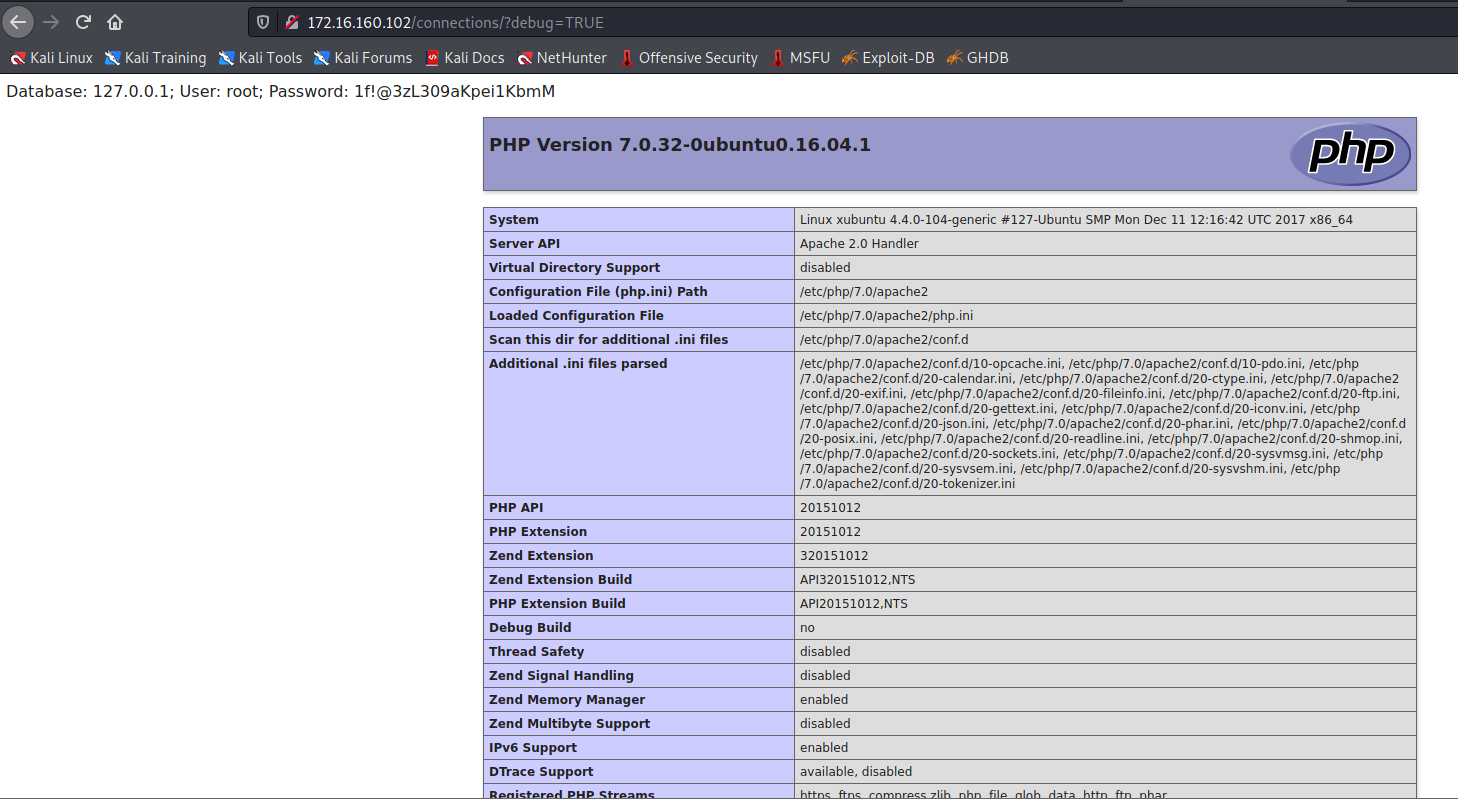
找到了一个隐藏资源http://172.16.160.102/connections/
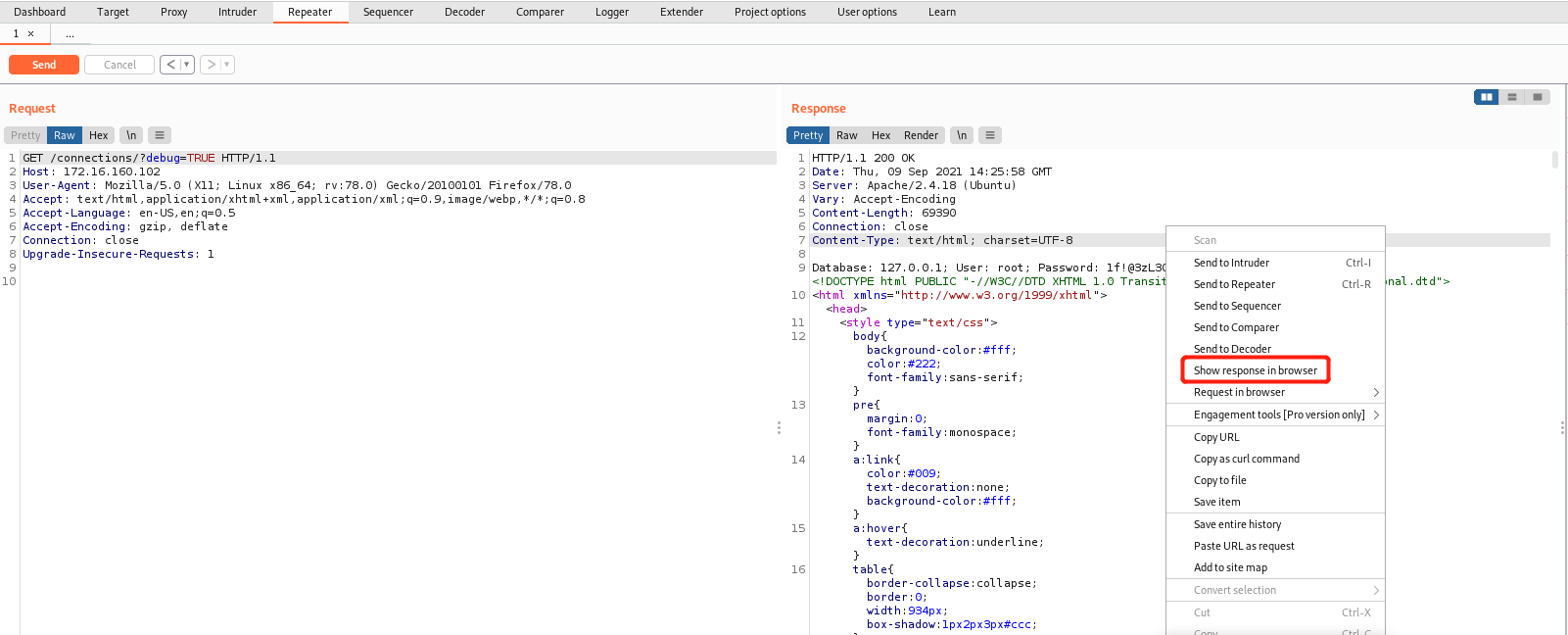
任务 4:使用 burp repeater 提取敏感信息
在robots.txt中,根据基于路径值的网址匹配
/*?debug=*匹配包含?debug=的任何路径
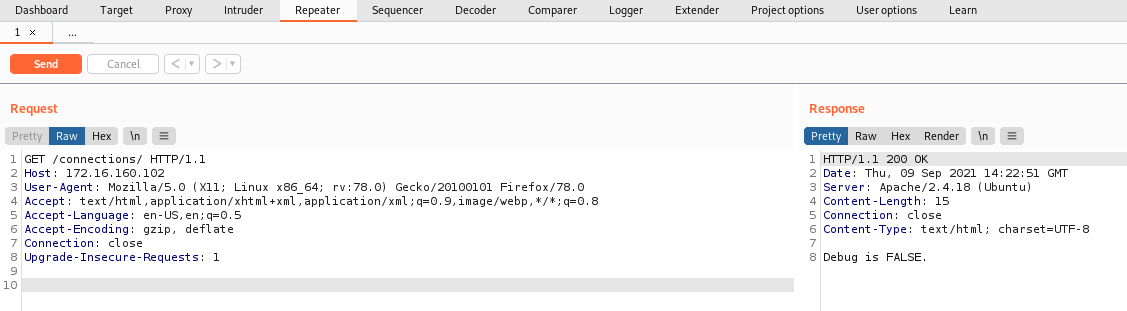
我的理解:/*?debug=*中的第一个*可以匹配:connections/,连接?debug=,第二个*匹配TRUE、FALSE等字符。
也就是说,这个规则可以匹配:/connections/?debug=TRUE,/connections/?debug=FALSE,/connections/?debug=。
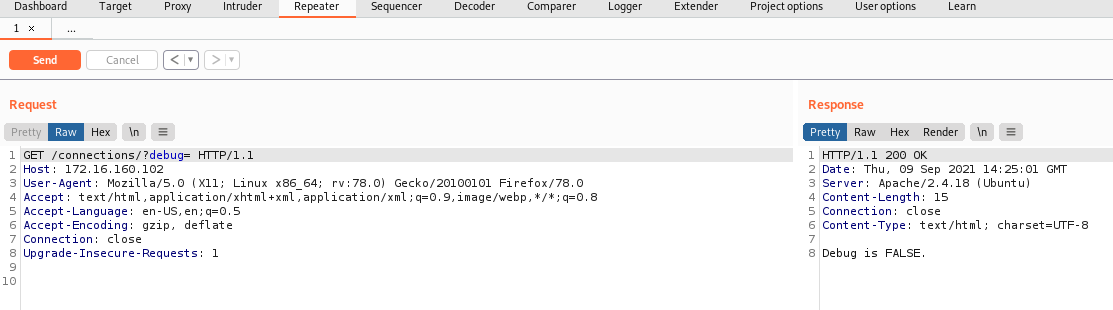
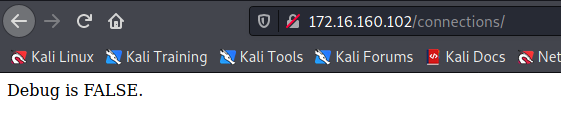
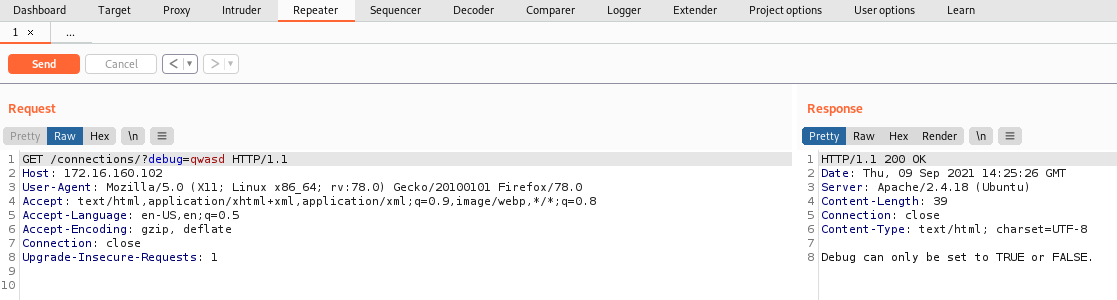
应用程序期望debug参数的值设置为 TRUE 或 FALSE。
将debug参数的致设置为TRUE。
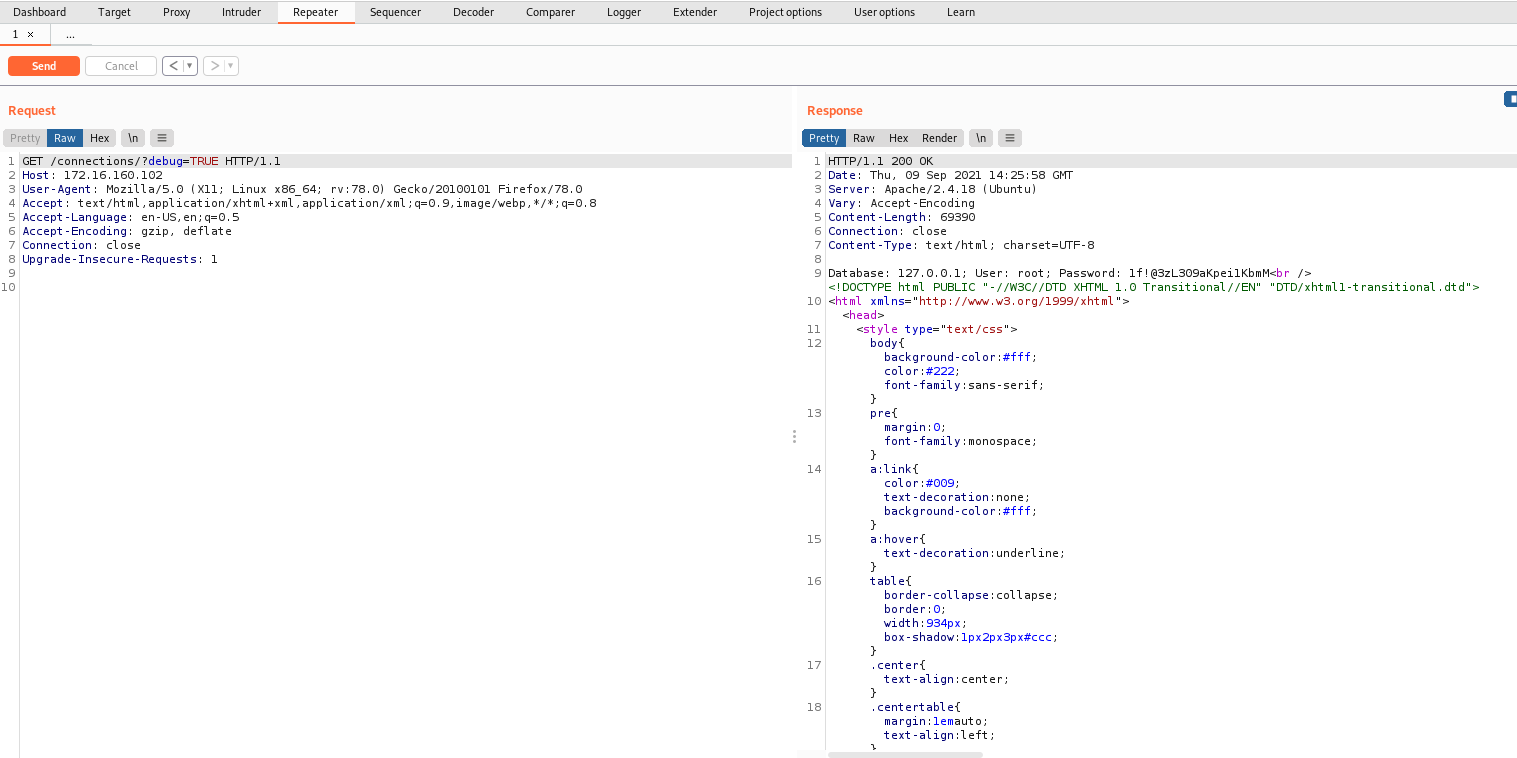
右键,Show response in browser